
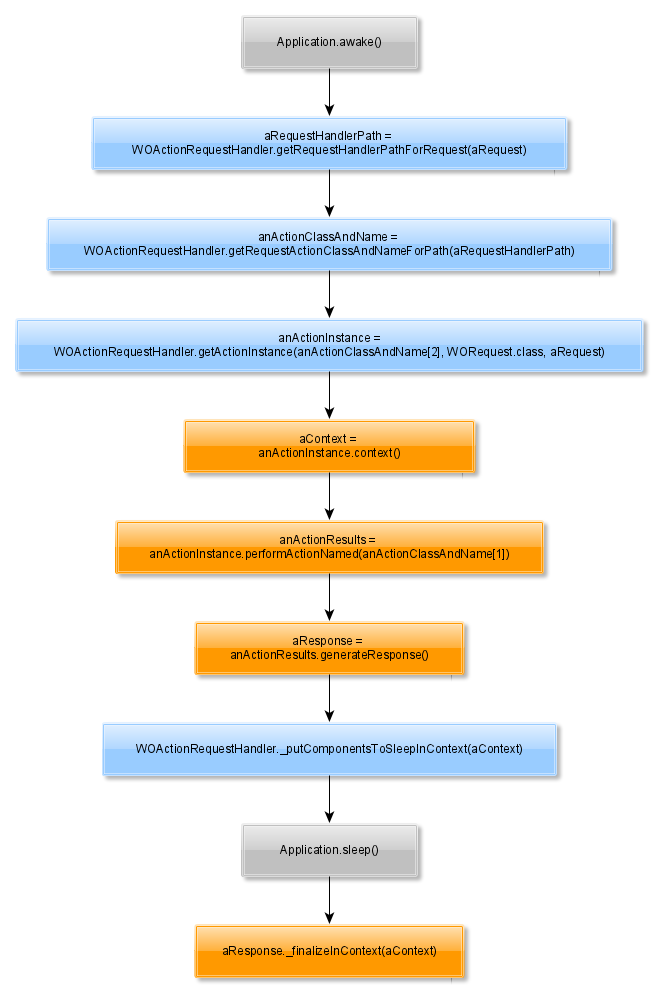
The next step builds the WOContext with data from the WORequest. The WOAction class (which is the abstract base class of WODirectAction which again is the base class for our resource classes) delegates the task to the WOApplication. Because the REST service is stateless and doesn’t generate webpages, we don’t change this process. The Request-Response-Loop can call the default implementation.
Blog Archives
Step 4: getActionInstance
Posted on February 13, 2019
This method will be called by the Request-Response-Loop to instantiate the resource class. The default implementation invokes the constructor of the given action class with the WORequest instance.
ERRest uses the method to initialize the newly created class. In our framework, there is nothing to do at the moment. We can use the default implementation. Maybe we can use other constructors here to set URIBuilder, which we need later for the Ids within the XMLMessages.
@SuppressWarnings("rawtypes")
@Override
public WOAction getActionInstance(Class anActionClass, Class[] parameters, Object[] arguments) {
BaseRestResource actionResource = (BaseRestResource) super.getActionInstance(anActionClass, parameters, arguments);
// TODO: init more things here
return actionResource;
}
The parameters of the method have been built by the getRequestActionClassAndNameForPath() – see last post.
Step 3: getRequestActionClassAndNameForPath
Posted on February 13, 2019
This method is very simple, it gets the NSArray<String> with class name and method name of the resource class. And it translates the data into an array of three Objects. The third object will be the Class for the given class name.
@Override
public Object[] getRequestActionClassAndNameForPath(@SuppressWarnings("rawtypes") NSArray requestHandlerPath) {
String requestActionClassName = (String) requestHandlerPath.objectAtIndex(0);
String requestActionName = (String) requestHandlerPath.objectAtIndex(1);
return new Object[] { requestActionClassName, requestActionName, _NSUtilities.classWithName(requestActionClassName) };
}
The method name will be called “actionName”, because the normal behaviour of WODirectActionHandler adds the term “Action” at the end of the method name and looks for such a method within the class. But we don’t longer support that.
The method implementation is exact the same as in ERRest.
Step 2: getRequestHandlerPathForRequest
Posted on February 13, 2019
In the last post we have registered Resource classes within the RequestHandler. The handler can now choose one of the classes to execute one of class methods for the current request. Now we have to implement the methods, which the Request-Response-Loop will call.
The method getRequestHandlerPathForRequest() will be called with a WORequest instance, so we have access to all the attributes of our incoming request.
It is a good place to check, whether or not we have a registered resource class, which defines an endpoint, which will match the requested URI. It returns a NSArray<String> to the Request-Response-Loop, the first entry is the class name for the action, the second String is the method name within the class. We cannot change this behaviour except we overwrite the whole RR-Loop.
Every resource class has been registered within the handler as instance of ResourceDescription. We have to transfer this object into other methods of the loop. ERRest uses the userInfo dictionary (NSDictionary) of the WORequest instance, to transfer REST specific data together with the request. It is a Map, which can store an Object in relation to a key name (String). But if you call request.userInfo(), you will get an immutable Map. You cannot add your own data. However the WORequest class allows it to replace the whole Map with request.setUserInfo(Map). This we will use:
NSMutableDictionary<String, Object> userInfo = new NSMutableDictionary<String, Object>(request.userInfo());
// TODO: find ResourceDescription
userInfo.put(RequestUserInfoKey.RESOURCE_DSCR.name(), dscr);
request.setUserInfo(userInfo);
The client must send a header “Accept” to define the requested media type of the response. The server will only generate application/xml and some vendor specific subtypes:
Accept: */*
Accept: application/xml
Accept: application/vnd.info.phosco.rest.Staff.v1+xml
Accept: application/vnd.info.phosco.rest.LocationList.v1+xmlSo we can check against the default */* or application/xml, and if it will not match, we return here an error 406 (Not Acceptable).
public class BaseRestRequestHandler extends WODirectActionRequestHandler {
protected boolean isAcceptableMediaType(String mediaType) {
return "*/*".equals(mediaType) || Pattern.matches("^application\\/(?:.*\\+)?xml$", mediaType);
}
protected List<MediaType> getAcceptableMediaTypes(String mediaTypes) {
List<MediaType> res = new ArrayList<MediaType>();
String[] types = mediaTypes.split(",");
for (String t : types) {
String[] extensions = t.split(";");
String name = extensions[0].trim();
if (!isAcceptableMediaType(name)) {
continue;
}
MediaType mType = new MediaType(name);
for (int idx = 1; idx < extensions.length; idx++) {
if (!extensions[idx].trim().startsWith("q=")) {
continue;
}
String[] values = extensions[idx].split("=", 2);
mType.setQuality(Float.valueOf(values[1]));
break;
}
res.add(mType);
}
Collections.sort(res);
return res;
}
@Override
public NSArray getRequestHandlerPathForRequest(WORequest request) {
NSMutableArray<Object> requestHandlerPath = new NSMutableArray<Object>();
List<MediaType> mediaTypes = getAcceptableMediaTypes(mediaType);
if (mediaTypes.isEmpty()) {
// TODO: generate error 406 response with special resource
}
return requestHandlerPath;
}
}
The MediaType class is a simple POJO, which holds a name and a quality number. We sort the media types by quality, so we try the type with the highest quality first. “*/*” will have a quality of 0.0 initially (try it at least).
public class MediaType implements Comparable<MediaType> {
private String name;
private Float quality;
public MediaType(String name) {
this.name = name;
this.quality = ("*/*".equals(name)) ? 0.0f : 1.0f;
}
public Float getQuality() {
return quality;
}
public void setQuality(Float quality) {
this.quality = quality;
}
public String getName() {
return name;
}
@Override
public int compareTo(MediaType other) {
return -1 * this.quality.compareTo(other.quality);
}
@Override
public String toString() {
return "[" + name + ";q=" + quality + "]";
}
}
After this initial check, we have to look for matching resources. As described in the last post, we look for the HTTP verb (GET, POST…) and the matching @Path annotation. If we cannot find such a resource, we will return NotFound (404) to the client.
Then we check the @Produces against the “Accept” header value. If we don’t find a matching ResourceDescription, we will return NotAcceptable (406).
The last check compares @Consumes with the “Content-Type” header value. If we don’t find a matching ResourceDescription, we will return UnsupportedMediaType (415).
At the end, we add the first matching ResourceDescription to the userInfo Map of the WORequest object. From there we extract the classname and method name for the return-value of getRequestHandlerPathForRequest().
Step 1: Register Resource Classes
Posted on February 13, 2019
In the last post we have registered a new RequestHandler class for the request key “/api”. But the handler doesn’t know, which actions should be executed for an incoming request.
We need some resource classes (ERRest called it Controller), which define endpoints (URIs). If the request contains an URI path like such an endpoint, the handler must instantiate the matching resource class and execute the matching method.
The method of the class must be declared for the used HTTP verb (like GET, POST, PUT…), so the handler would choose it to execute. We use also the “Accept” header of the request, to find a matching class method. The method should declare, that it can generate such media type. If not, we will use another method or return “Not Acceptable” as HTTP error code (406).
Some requests will send data within the request body (content). This content has a “Content-Type” header, which should also match the media type the method can handle. There must be a matching method parameter, which awaits this data structure from the request body. If not, we will use another method or return the HTTP status “Unsupported Media Type” (415)
HTTP verb
The HTTP verb of the request we can extract from the given WORequest object. This will be the first step:
protected String getHttpVerbFromMethod(Method method) {
for (Annotation a : method.getAnnotations()) {
if ((a instanceof GET) || (a instanceof POST) || (a instanceof PUT) || (a instanceof DELETE)) {
return a.annotationType().getSimpleName();
}
}
return null;
}
// clazz is the Class object of the resource
for (Method method : clazz.getMethods()) {
String verb = getHttpVerbFromMethod(method);
// do something
}
The verbs can be enhanced, if necessary (like OPTIONS or HEAD). For the moment we only use the defined four verbs.
Media Types
To declare these media types we will use the annotations from JSR311. There is a @Produces annotation, which defines the media types the method can generate and send back to the client (should match the requested “Accept” header). There is a special media type “*/*” which match all media types. If the method defines explicitly a @Produces annotation, it can implicitly also answer all requests for Accept=*/*.
The method can also declare a @Consumes annotation, which defines the media type the method can handle (must match the request’s “Content-Type”). The “Content-Type” can also be null (no header defined). If the @Consumes has been declared, but no explicit media type has been set, it assumes implicitly “*/*”. If there is a “Content-Type=*/*” within the request, all methods should match, if there is no “Content-Type”, we could also execute every method. The matching method parameter would contain in this case the value “null”. In all other cases “Content-Type” must exact match @Consumes, to execute the method.
@POST
@Produces("application/vnd.info.phosco.rest.Location.v1+xml")
@Consumes("application/vnd.info.phosco.rest.Location.v1+xml")
public LocationMessage newLocation(LocationMessage xml) {
// store the new Location into database
}
In the example above we await an “application/vnd.info.phosco.rest.Location.v1+xml” (@Consumes) within the request body (as XML). These data contain an incomplete Location, which we use to create a complete new Location within our database backend. If we have create the entity, we will return this newly created entity within the HTTP response (also as XML). It will also have the content type “application/vnd.info.phosco.rest.Location.v1+xml” (@Produces). The class method newLocation() will only be called on POST requests (@POST).
To pre-process the @Produces/@Consumes information, we extract the data during the registration step of the resource class:
protected Set<String> getConsumeMediaTypeFromClassOrMethod(Class<? extends BaseRestResource> clazz, Method method) {
Consumes consumes = method.getAnnotation(Consumes.class);
if (consumes == null) {
consumes = clazz.getAnnotation(Consumes.class);
}
Set<String> mediaTypes = new HashSet<String>();
if (consumes != null) {
mediaTypes.addAll(Arrays.asList(consumes.value())); // remove double entries
return new ArrayList<String>(mediaTypes);
}
mediaTypes.add("*/*");
return new ArrayList<String>(mediaTypes);
}
protected Set<String> getProduceMediaTypeFromClassOrMethod(Class<? extends BaseRestResource> clazz, Method method) {
Produces produces = method.getAnnotation(Produces.class);
if (produces == null) {
produces = clazz.getAnnotation(Produces.class);
}
Set<String> mediaTypes = new HashSet<String>();
if (produces != null) {
mediaTypes.addAll(Arrays.asList(produces.value()));
}
mediaTypes.add("*/*");
return new ArrayList<String>(mediaTypes);
}
// clazz is the Class object of the resource
for (Method method : clazz.getMethods()) {
Set<String> consumes = getConsumeMediaTypeFromClassOrMethod(clazz, method);
Set<String> produces = getProduceMediaTypeFromClassOrMethod(clazz, method);
// do something
}
We will use the declared media types of the method, or if there isn’t one defined, will use the class media types. Both annotations allow multiple media types, so we must prevent double entries.
Resource Path
To differ the resource classes we define the path for the URI with the @Path annotation on every class. This annotation is also defined within JSR311. We can define these annotation on class level or method level.
@Path("/location-list/{location-id}
public class LocationResource extends BaseRestResource {
}
The example defines a path “/location-list/{location-id}” for the whole class. So the request handler will use this resource class for an URI like:
http://127.0.0.1:10002/cgi-bin/WebObjects/api/location-list/24565The URI will match the @Path after “/api”. Parts of the @Path which are enclosed into “{}” are dynamic parts. They will be set by the client according to the necessary data. We will use them as Id, in the example “24565” will be the Id of the request Location entity. The resource class must query the database for this specific Location and must return the data within the response body. You can directly use the Ids from the database, but it is also possible to hide these information, i.e. by using UUIDs.
Every method can have parameters, which the handler should fill with the correct request-specific values. JSR311 defines a lot of annotations, which define sources for the parameters:
@HeaderParam
It defines a header key name, so the handler should read the HTTP header value and store it into the annotated parameter variable.
@CookieParam
It defines a cookie key name, so the handler should read the cookie value and store it into the annotated parameter variable.
@QueryParam
The annotation declares a name of a query-string parameter (the part after the “?” within the requested URI). The associated value should be stored into the annotated variable. The query string is URLencoded, so we have to decode the value within the handler class.
@PathParam
Here we can define the name of a “dynamic part” of the declared URI (within @Path annotation). In the example above we could use “location-id” as parameter. The name of the @PathParam must match the name of a “{}” part within @Path (case-sensitive!). For the example the annotated variable must i.e. contain “24565”.
@DefaultValue
Every parameter can be annotated with a second annotation, which defines a default value. If the parameter cannot be filled by the request handler (i.e. the header key defined by @HeaderParam doesn’t exist within the current request object), the variable should then contain the declared default value.
The variables can have different types. JSR311 allows primitive types like int, long, boolean, double and so on. Allowed are also classes, which have a constructor with a single String parameter. Classes with a static method valueOf(String) are also possible and List<String> classes. According to the declared method parameter type, the handler will instantiate the correct class.
During the register workflow we cannot store values for the most of the parameters, because they are only known at the request time. But we can pre-process the path parameters. If we find @PathParam annotation at request time, we must look into the @Path annotation to find the right place of the parameter and must extract the matching characters from the request URI. This we could do with Regular Expressions. We would generate a pattern for the @Path declaration of every class/method and the “dynamic parts” would be replaced by RegEx groups. So we can say, that the “location-id” would be the group number 1 and if we use the pattern for the requested URI, we will get the matching substring for the group:
protected PathRegEx buildRegularExpressionFromPath(String path) {
Map<String, Integer> params = new HashMap<>();
int groupNumber = 0;
String str = trim(path, '/');
String res = "";
for (String part : str.split("/")) {
if (part.startsWith("{") && part.endsWith("}")) {
params.put(trim(trim(part, '{'), '}'), ++groupNumber);
part = "(\\d+)"; // allow only numbers as Id, enhance this?
}
res += ("\\/" + part);
}
res = "^" + res.substring(2) + "$";
return new PathRegEx(res, params);
}
protected String getPathFromClassOrMethod(Class<? extends BaseRestResource> clazz, Method method) {
Path path = method.getAnnotation(Path.class);
if (path == null) {
path = clazz.getAnnotation(Path.class);
}
return path == null ? null : trim(path.value(), '/');
}
// clazz is the Class object of the resource
for (Method method : clazz.getMethods()) {
String path = getPathFromClassOrMethod(clazz, method);
PathRegEx regex = buildRegularExpressionFromPath(path);
// do something
}
First we extract the @Path annotation for every class method. If there is no one, we will use the annotation on class level. If the class has also no annotation, we cannot execute an action for this class. The path can contain trailing and leading slashes, so we have to remove them (the request path won’t have them too).
From the path we generate a RegEx pattern. Every “dynamic part” will be replaced with “(\d+)”, so we await only numbers for a path parameter. JSR311 defines more characters ([0-9a-zA-Z], underscore and minus). If we need that, we can enhance it.
“(\d+)” is a group of the regular expression. So if we use a Matcher, we can access the parameters by the group index. Group 0 is always the full match (complete pattern), group 1 is the first parameter, group 2 the second parameter and so on. Depending on the depth of the relations between the objects, there can be more than one group:
/person-list/{person-id}/function-list/{function-id}/location-list/{location-id}will be:
^person-list/(\d+)/function-list/(\d+)/location-list/(\d+)$Group 1 matches {person-id}, group 2 matches {function-id} and group 3 matches {location-id}. The example would return the function of a person on a specific location: a physician (person) can be the chief doctor (function) in a hospital (a location) but only an expert witness (function) on a laboratory (other location).
The method buildRegularExpressionFromPath() (see Java code above) stores every parameter name together with its group index within a Map. So we can later find the index to a given the name (the name comes from @PathParam annotation).
Return value
WODirectActions should always return WOActionResults, which is an interface to WOResponse. But we will return the matching message class, which the framework JAXB will transform into an XML representation (response content). This representation will added to the WOResponse together with an HTTP status of 200 (OK). This code we could move into a super class, to prevent a lot of boilerplate code within the resource class.
Preprocessing
How we can handle all these metadata of a class? I think we should extract them during the registering of the resource classes on the request handler. We must announce the resources to the handler within the Application class constructor (btw. we could also automatically scan the WebObjects classpath for resource classes), so we can store the resource classes into a list within the handler. But it is not enough. Take a look on the questions we have to answer during the Request/Response-Loop:
- Does the request URI match the @Path?
- Does the Accept header match the @Produces?
- Does the Content-Type header match the @Consumes?
- Does the HTTP verb match the annotation?
- Does the method use a return value, which JAXB can translate into the media type?
- Does the method have a parameter, which can be filled with the JAXB-translated content of the request?
To speed up the execution of a request on the server, we should pre-process as much as we can during the registration time on application initialization.
The examples above show you, that we should store the metadata for every method. An action method is the smallest entity, the request handler will call. We need the following data:
Class name
Method of the class
Path
Regular expression and group indexes
consuming media type
producing media type
Because every method can define more than one media types, we should store only one media type per registration and have to duplicate the registration for other declared media types.
To find the registered resource very fast we use Map<String, Set<ResourceDescription>>, where String contains a key to find a quick answer to the 6 questions above. So we store a set of all methods, which define the @GET annotation for a key “GET”. This allows us to answer the 4th question very quick:
Set<ResourceDescription> get = registerdVerb.get("GET");
We can get for every question a Set<ResourceDescription> and to find the matching ResourceDescription we build the intersection of the sets. To get a list of all GET methods which also match the requested URI we can do:
Set<ResourceDescription> exp = new HashSet<ResourceDescription>();
for (String regex : this.registeredRegEx.keySet()) {
if (!Pattern.matches(regex, uri)) {
continue;
}
exp.addAll(this.registeredRegEx.get(regex));
}
Set<ResourceDescription> get = registeredVerb.get("GET");
exp.retainAll(get);
The example matches the URI from the request against the registered RegEx pattern, which we have pre-processed from the @Path annotation. If the pattern will match, we store the ResourceDescription within a Set and then we build the intersection with the set of registered resources for the GET verb. The result is a set of ResourceDescriptions which will match both properties, the HTTP verb and the URI.
The next steps build further intersections with the media types of @Produces and @Consumes. At the end we get a small set of ResourceDescription. Actually it should contain only one. We choose the first ResourceDescription and have enough information within to instantiate the resource class and call the action method.
To prevent double registrations of resource classes we implement equals() and hashCode() on ResourceDescription. The implementation of the Set class will do the rest for us.
The advantage of this workflow is the speed. We can find the resource very quick. The disadvantage is the amount of memory we need. We have to handle multiple Map<String, Set<ResourceDescription>>. But the description classes are always the same (immutable), only the memory for the Set/Map classes is necessary.
WebObject’s DirectAction for Rest
Posted on February 8, 2019
The ERRest framework uses DirectActions within WebObjects to handle REST requests. It registers a handler class (subclass of WODirectActionRequestHandler) for a specific part of the URI (“/ra”). It is called request handler key. We could set another key like “/api”, to differ client URIs and server URIs.
public class BaseRestRequestHandler extends WODirectActionRequestHandler {
public static void register(BaseRestRequestHandler requestHandler) {
WOApplication.application().registerRequestHandler(requestHandler, "api");
}
}
Within the constructor of the Application class we will register our MessageRequestHandler, which is a subclass of BaseRestRequestHandler:
public class Application extends ERXApplication {
public Application() {
BaseRestRequestHandler requestHandler = new MessageRequestHandler();
BaseRestRequestHandler.register(requestHandler);
setDefaultRequestHandler(requestHandler);
}
}
Now, all our requests to /api will be redirected to our MessageRequestHandler. And our application redirects all requests to our own handler per default (with setDefaultRequestHandler()). How does it work?
Request-Response-Loop
WebObjects handles requests during its Request-Response-Loop. There is a class WORequestHandler, which processes the request in its handleRequest(WORequest) method. It is an abstract class, which is used by a private class WOActionRequestHandler. This class implements the abstract method handleRequest(WORequest), which calls _handleRequest(WORequest) and returns a WOResponse object. The _handleRequest(WORequest) method implements the complete handling of the request, which subclasses can modify by overwriting the used methods. These are:
If we look into ERRest, the class ERXRouteRequestHandler overwrites the four blue colored methods. The first and second method will be re-implemented, so the default algorithm has been replaced. The third and fourth method extends the algorithm of the base-class WODirectActionRequestHandler. The latter only implements getRequestHandlerPathForRequest(), so we can focus us on the code of WOActionRequestHandler.
Excursion: What are ActionNames?
As you can see in the image above, the second method extracts a so called action name and the third blue method uses it to create an instance of a class. A normal direct action URI of a WebObjects application looks like:
http://127.0.0.1:10001/cgi-bin/WebObjects/DirectActionTest.woa/wa/queryLocation?filter=LeipzigqueryLocation is the ActionName. It will be enhanced by the term “Action”, so you need a method queryLocationAction() within your handler class. Per default, your handler class is named as DirectAction, which is registered for the key “/wa”. If your URI contains another key, you have to register an own class:
http://127.0.0.1:10001/cgi-bin/WebObjects/DirectActionTest.woa/testme/queryLocation?filter=Leipzig“/testme” needs another request handler (subclass of WODirectActionRequestHandler), which must be registered as direct action handler. It defines the class name which will execute the given action name (TestMeAction and queryLocationAction).
public class TestMeRequestHandler extends WODirectActionRequestHandler {
public TestMeRequestHandler() {
super("TestMeAction", "noOp", true);
}
@Override
protected String defaultActionClassName() {
return "TestMeAction";
}
@Override
protected String defaultDefaultActionName() {
return "noOp";
}
}
public class TestMeAction extends ERXDirectAction {
public DirectAction(WORequest request) {
super(request);
}
public WOActionResults noOpAction() {
// default action, if we don't define an action name in URI
return pageWithName(Main.class.getName());
}
public WOActionResults queryLocationAction() {
// TODO: query datastore and put data into page
return pageWithName(Main.class.getName());
}
}
public Application extends ERXApplication {
public Application() {
WODirectActionRequestHandler reqhandler = new TestMeRequestHandler();
WOApplication.application().registerRequestHandler(reqHandler, "testme");
}
As you can see, the DirectAction workflow needs always a class, which can handle the action and an action name, which is mapped to a method of this class.
Therefore the method getRequestActionClassAndNameForPath() of WOActionRequestHandler works with an array of two parameters: the class and the action name. Our own implementation must return such data.
XML-Rest interface with hyperlinks
Posted on February 6, 2019
I try to create a REST interface which sends/receives XML messages. For the fun factor I choose WebObjects 5.4.3 and Wonder 6, which comes with a framework called ERRest, that I can use for my project. I have a working client based on GXT, which play against a Glassfish server with JavaEE6. They communicate per Rest-XML, so I think it could be possible to replace the server implementation with a WebObjects server.
The interface
I have to use HTTP as the protocol layer. The messages are in XML. Every message has it’s own Content-Type header, the client sends this type to classify the XML messages to the server. It also generates Accept headers to declare allowed messages (i.e. for POST requests, which return a new entity, formatted in an XML of a specified type).
The server can check both headers on the resource/route endpoints (@Consumes und @Produces annotations of Jax-RS). Errors within this workflow will result in HTTP error codes (415 if Content-Type not equals to @Consumes, 406 if Accept not equals to @Produces).
Additional the server uses ETags and If-Match/If-None-Match header to reduce the transmitted data.
The XML data contain only the necessary data fields, to represent the response for the prior request. Every relationship and every Id are hyperlinks, which the client can call, to get more detailed data.
So you can have a company, which has different locations. If you ask for the company, you will use an URI like with a GET method (Accept=application/vnd.info.phosco.rest.Company.v1+xml):
http://127.0.0.1:10001/api/company-list/25This will return the company with the Id=25 (Content-Type=application/vnd.info.phosco.rest.Company.v1+xml):
<company id="http://127.0.0.1:10001/api/company-list/25">
<name>TestCompany</name>
<type>LIMITED</type>
<link rel="staff-list" "http://127.0.0.1:10001/api/company-list/25/staff-list" />
<link rel="location-list" href="http://127.0.0.1:10001/api/company-list/25/location-list" />
</company>The client has now the chance to get more data with subsequent calls. It can get a list of all company staff by calling the hyperlink for the link “staff-list”. Or, it can get a list of all locations of the company by calling the link behind the “location-list” relation. The type could be an enumeration, the name is a simple text. The id of the company (where you can get these data structure again) you can find a attribute of the root node.
You can now ask the server for the company-list. It will be an array of such company structures. Again you use a GET method on HTTP (Accept=application/vnd.info.phosco.rest.CompanyList.v1+xml
http://127.0.0.1:10001/api/company-listThis will return (Content-Type=application/vnd.info.phosco.rest.CompanyList.v1+xml):
<company-list id="http://127.0.0.1:10001/api/company-list" size="2">
<company id="http://127.0.0.1:10001/api/company-list/2">
<name>MyCompany</name>
<type>LIMITED</type>
<link rel="staff-list" "http://127.0.0.1:10001/api/company-list/2/staff-list" />
<link rel="location-list" href="http://127.0.0.1:10001/api/company-list/2/location-list" />
</company>
<company id="http://127.0.0.1:10001/api/company-list/25">
<name>TestCompany</name>
<type>LIMITED</type>
<link rel="staff-list" "http://127.0.0.1:10001/api/company-list/25/staff-list" />
<link rel="location-list" href="http://127.0.0.1:10001/api/company-list/25/location-list" />
</company>
</company-list>Theoretically it should be possible to return only Ids of companies within the list. But you ask for a list to display some information about the entities. So it is better to return useful data about the list-entities. In the other case you have to create n subsequent calls (one for every list entity), to bring up a list-element on the client.
The next point are filtered lists and paging of lists. It could be possible to declare a filter (like a pattern for the company name) and the server should only return all matching company entities. So it is necessary to send the filter to the server. Also it could be possible, that the list are to huge for the client view, so it could be better to define a start/end for a sub-list. For example, the complete list contains 100 entities, but you can only display 10 entities on the screen. Then you have to remove them and display the next 10. On the second page you have a start=11 and an end of 20, third page displays companies from Id 21 till 30 and so on. This is called paging.
The client generates now query parameters “filter”, “offset” and “limit”. These are optional parameters. “filter” holds a String, “offset” ist the page start (zero-based) and “limit” is the maximum length of the page (list). The returned list can be smaller, but never longer. Let’s try:
http://127.0.0.1:10001/api/company-list?filter=MyCompany&offset=0&limit=10This would get a list of maximal 10 company records, starting at position 0 and the name must contain “MyCompany”. The server decides, how the filter will work. Should the work somewhere within the name occur or at the beginning? Is the filter case-sensitive? Works it on the name or the type attribute? That ist part of the business logic.
There are default values for the optional parameters: If the filter does not exist, all companies will be returned. If the offset is missing, it will be replaced by “0”, if the “limit” not in the query, it will be Integer.MAX_VALUE (return all elements – no paging). Let’s try:
<company-list id="http://127.0.0.1:10001/api/company-list" filter="MyCompany" offset="0" limit="10" size="2">
<company id="http://127.0.0.1:10001/api/company-list/2">
<name>MyCompany</name>
<type>LIMITED</type>
<link rel="staff-list" "http://127.0.0.1:10001/api/company-list/2/staff-list" />
<link rel="location-list" href="http://127.0.0.1:10001/api/company-list/2/location-list" />
</company>
<company id="http://127.0.0.1:10001/api/company-list/25">
<name>That's MyCompany</name>
<type>LIMITED</type>
<link rel="staff-list" "http://127.0.0.1:10001/api/company-list/3/staff-list" />
<link rel="location-list" href="http://127.0.0.1:10001/api/company-list/3/location-list" />
</company>
</company-list>The question is now, how I can program that with ERRest?
The server workflow
On the server we need classes, which can handle HTTP requests. They must differ between GET, POST, PUT, DELETE,… verbs and call the associated resources.
There must be classes which implement the logic, the resources, which are associated to a HTTP verb and an URI path. They must also define, which Content-Type they accept or return.
The HTTP requests contain XML documents, which must be parsed and translated into objects. With JavaEE6 the Jax-RS framework brings message readers, which generate the objects from XML. These messages are POJOs, which the resource methods use to modify the database backend.
For the response the resource classes will generate message objects with the data, the Jax-RS message writer will build XML documents of them, which are added to the HTTP response body. Every response will have a Content-Type.
The ETag must be calculated from the last-modified-time and the Id of the object. Then the server can compare the ETag sent by the client (If-None_Match header) with the pre-calculated ETag of the object. If the ETags differ, the server send the updated objects. If the ETags are equal, the server will send a HTTP code 304 (Not Modified). The ETag will be re-calculated on POST/PUT/PATCH verbs.
Any error within the stack will be mapped to HTTP error codes, so the client can handle these like a browser application.
The client workflow
A client will generate request to URIs, which come from the previous server responses. The first URIs the client will get from a service document, which contains all the possible root resources.
For POST/PUT/DELETE the client must generate XML fragments and a special Accept header. So we need XML writer and reader, which parse the fragments (from response) or create fragments (from POJOs). We need also a workflow for handling the ETags.
The client must recognize error responses and build some special error pages or states. The client holds the complete state of the application. The server is stateless. All entities must be cached on client side, so we have access to a lot of links, which we can use to go forward within the application.
Every request must contain a BaseAuth, which the server checks against a user management tool (like LDAP or database).
The ETag comes with the response from the server and must be stored on client side on every related object. So it is available, if the client will query data from the server and must be set on every request (If-None-Match header). It can be also used as concurrency control. If another client has changed data on the server, it will have a new ETag. So we can prevent updates on an already changed object on the server (optimistic lock on client).
Find all running hosts within subnet
Posted on February 1, 2019
To find all running hosts within a subnet, you can ping it with fping:
fping -s -g 192.168.1.1 192.168.1.254 2>/dev/null | grep "is alive"Extract the Java version of a .class file
Posted on January 31, 2019
Every Java Class file has been compiled with a specific Java version. To get the version try:
/path/to/jdk/bin/javap -verbose ClassFile | grep "version:"Here is the list of all currently known Java versions:
Java 1.2 uses major version 46
Java 1.3 uses major version 47
Java 1.4 uses major version 48
Java 5 uses major version 49
Java 6 uses major version 50
Java 7 uses major version 51
Java 8 uses major version 52
Java 9 uses major version 53
Java 10 uses major version 54
Java 11 uses major version 55
Copy a project from SVN repository to another
Posted on February 14, 2018
Sometimes I program some stuff at home but I need it later on my work office. It is necessary to move the project from my private SVN repository to the work repository. I need all the revisions, not only the latest one.
First at all, I have to dump the project at home:
# svnadmin dump path/to/home/svn > repository.dmp
The path/to/home/svn must be a local path, so you have to work on the repository machine (you cannot use svn+ssh etc.). The dump contains now the whole repository, all revisions. So it can be huge. To filter the relevant project there is a tool called svndumpfilter.
# cat repository.dmp | svndumpfilter --drop-empty-revs --renumber-revs include /path/name_of_the_project/in/svn > project.dmp
You have to use the case-sensitive project name (inclusive the parent folder names within SVN). Now copy the project.dmp to the SVN repository server on your work office. Again you have to work on the repository machine to use a local file path.
To load the project use:
# svnadmin load --ignore-uuid /path/to/work/svn < project.dmp
This will import the project on the root folder / of the repository. It contains all the folders and subfolders of the source repository, where the project was located there. So if your original project path was
/projects/webobjects/example
the destination path will be
/projects/webobjects/example
too. To prevent overwriting existing stuff, you can use the --parent-dir switch during the load operation:
# svnadmin load --ignore-uuid --parent-dir /projects/phosco/examples /path/to/work/svn < project.dmp
So the resulting path will be
/projects/phosco/examples/projects/webobjects/example
You have to move the imported project on the right position later. If you have tested the command above, you have seen an error. This is a problem of the source folder of the project, it doesn’t exist on the destination repository. Before you can load the project dump, you have to create the base folder:
svn mkdir -m "Creating new project layout." file:///path/to/work/svn/projects/phosco/examples/projects
You have to use an URI to access the repository with svn. You cannot use the local path as with svnadmin. It is necessary to create only the first component of the project path (not the deeper subfolders):
Location on the source SVN:
/projects/webobjects/example
Build on the destination SVN:
projects
Together with the parent-dir of the destination repository you have to create a folder
/projects/phosco/examples/projects
Now you can load the project into the destination repository:
# svnadmin load --ignore-uuid --parent-dir /projects/phosco/examples /path/to/work/svn < project.dmp
The last step it the move of the newly imported project to the correct place within the destination repository:
svn move -m "move the imported project to the right location" file:///path/to/work/svn/projects/phosco/examples/projects/webobjects/example file:///path/to/work/svn/projects/phosco/examples/new-example